How AI Agents Like Llama 3.2 1B Process Information
A hands-on review of how Llama 3.2 1B processes information, solves real-world problems, and adapts to diverse tasks, from project management to creative writing.
AI Agents
Llama 3
Reasoning
Content Generation
AI Evaluation
Creative AI
Automation
AI agents are redefining how we handle information, solve problems, and make decisions. Among these agents, Llama 3.2 1B stands out for its compact yet powerful architecture, designed to process information with efficiency and accuracy. But how well does it perform when tasked with real-world challenges?
In this blog, we’re taking a hands-on approach to test Llama 3.2 1B and evaluate how it reasons as an AI agent. Through practical scenarios, we’ll explore its ability to process inputs, analyze data, and deliver insightful solutions. By examining its performance, we’ll uncover the strengths, weaknesses, and potential of Llama 3.2 1B in dynamic applications. If you’re intrigued by the mechanics of AI reasoning, join us as we put this lightweight yet powerful model to the test.
Task 1: Content Generation
Prompt: When user says “Start” you should:
Content Generation: Write a comprehensive, informative article about project management fundamentals, with a specific focus on defining objectives, scope, and delegation.
Initial Task Understanding and Planning
(0:06) Thought: Can you provide details about the current task or project we are working on, including any objectives, deadlines, and specific requirements?
(0:09) Thought: Gather information on project management fundamentals, with specific focus on defining objectives, scope and delegation.
Choosing a Research Tool and Initial Search
(0:16) Thought: To write a comprehensive article on project management fundamentals, I need to gather detailed information on defining project objectives, scope, and delegation. I’ll start by using the wikipedia tool to get a broad overview of project management, which might include these components.
Using tool: wikipedia
Refining the Search Strategy
(0:18) Thought: The wikipedia entry provides a good overview of project management, but it lacks specific details on defining objectives, scope and delegation. I’ll use google_serper to find more targeted information on these aspects.
Using tool: google_serper
Further Research Using Google Search
(0:22) Thought: I’ve gathered some insights on defining project objectives. Now, I need to delve into the specifics of scope and delegation. I’ll use google_serper again to find detailed information on these topics.
Using tool: google_serper
(0:26) Thought: I’ve gathered some insights on defining project objectives and scope. Now, I need to delve into the specifics of delegation in project management. I’ll use google_serper again to find detailed information on this topic.
Using tool: google_serper
Output Snippet:
The output is an article titled “Project Management Fundamentals: Defining Objectives, Scope, and Delegation”. It provides a detailed explanation of these three key aspects of project management.
Time Taken: The agent starts working on the task at 0:06 and the final output is displayed at 0:32, indicating a time taken of 26 seconds.
Readability:
Flesch-Kincaid Grade Level: 13
Flesch-Kincaid Score: 12.97
Summary Length: 346 words
Analysis of the Agent’s Thought Process:
Task Understanding: Correctly identifies the requirements based on the initial prompts.
Strategic Tool Selection: Starts with Wikipedia, then switches to Google Search for more targeted research.
Iterative Research: Refines search strategy, focusing sequentially on objectives, scope, and delegation.
Adaptability: Changes approach when initial search lacks detail.
Conclusion:
The agent generates a well-structured, informative article on project management fundamentals, demonstrating logical and strategic research and adaptability throughout the process.
Task 2: Calculation
Prompt: A company sells two products: Product A and Product B. Product A costs $30 per unit to produce and sells for $50 per unit. Product B costs $40 per unit to produce and sells for $70 per unit.
The company sold 120 units of Product A and 80 units of Product B last month. Calculate the total revenue generated from the sales of both products.
Calculate the total profit generated from the sales of both products (Revenue – Total production cost).
The company wants to increase the total revenue by 10%. How many additional units of each product must they sell to achieve this goal, assuming the production cost per unit and selling price per unit remain constant?
Initial Task Understanding
(0:06) Thought: Calculate the total revenue and total profit from the sales of Product A and Product B, and determine how many additional units of each product must be sold to increase total revenue by 10%.
Analysis of the Agent’s Thought Process:
The agent correctly understands the task: calculate total revenue, total profit, and additional units needed for a 10% revenue increase.
Bot Output Snippet:
For Product A:
Total revenue = (120 units * $50) = $6000
Total production cost = (120 units * $30) = $3600
Total profit = $6000 – $3600 = $2400
For Product B:
Total revenue = (80 units * $70) = $5600
Total production cost = (80 units * $40) = $3200
Total profit = $5600 – $3200 = $2400
Combined results:
Total revenue = $6000 + $5600 = $11600
Total profit = $2400 + $2400 = $4800
To increase total revenue by 10%:
Target revenue = 11600 + (11600 * 0.10) = $12760
Time Taken: 16 seconds (from receiving the prompt at 0:06 to output at 0:22)
Summary Length: 59 words
Analysis of the Output:
Accurate Calculations: Revenue and profit calculations are correct.
Clear Presentation: Easy-to-follow format.
Incomplete Solution: Does not show steps for calculating additional units needed for 10% revenue increase.
Incorrect Answer: The “30 additional units of Product A and 20 of Product B” suggested is not mathematically accurate.
Conclusion:
The agent understands and completes the core calculations but lacks detailed steps for the additional units calculation, and the final combination is not correct.
Ready to grow your business?
Start your free trial today and see results within days.
Prompt: Summarize the key findings from the previous article in 100 words, focusing on the most significant sections.
Initial Task Understanding
(0:06) Thought: Summarize the key findings from the previous article in 100 words, focusing on the most significant sections.
Analysis of the Agent’s Thought Process:
The agent directly restates the prompt, indicating basic understanding.
Analysis of the Output:
Conciseness: Delivers a 97-word summary.
Content: Accurately covers AI reasoning, applications, recent advancements (OpenAI), and ethical considerations.
Structure and Clarity: Well-organized and easy to read.
Snippet of Bot Output:
The article delves into the realm of AI reasoning, exploring its types, historical evolution, and applications in healthcare and beyond. It underscores the role of AI reasoning in decision-making, problem-solving, and fostering innovation. A specific focus is placed on recent advancements such as OpenAI’s GPT-3 Model, detailing its features and performance. Furthermore, the article raises awareness about the challenges and ethical considerations surrounding AI reasoning models. Overall, it provides a comprehensive overview of the significance and implications of AI reasoning in various fields, shedding light on its potential and limitations.
Conclusion:
The agent is able to summarize complex information accurately and concisely within the specified word limit.
Task 4: Comparison Task
Prompt: When user says “Start” you should:
Compare the environmental impact of electric vehicles with that of hydrogen-powered cars. Include factors such as energy production, vehicle lifecycle, and emissions.
Initial Task Understanding and Information Gathering
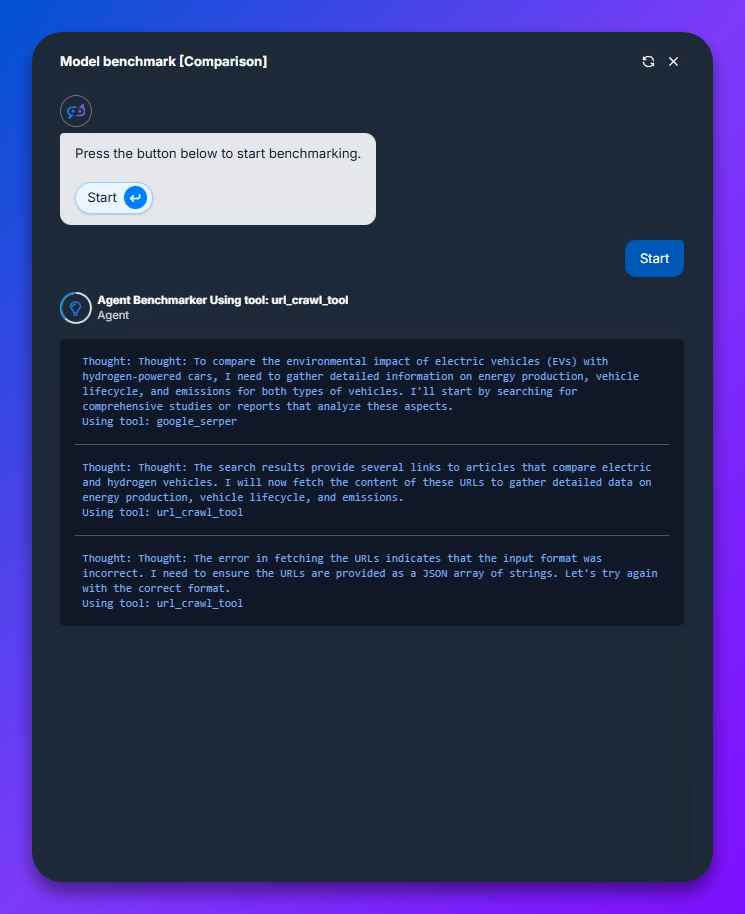
Thought: To compare the environmental impact of electric vehicles (EVs) with hydrogen-powered cars, I need to gather detailed information on energy production, vehicle lifecycle, and emissions for both types of vehicles. I’ll start by searching for comprehensive studies or reports that analyze these aspects.
Using tool: google_serper
(0:15) Thought: The search results provide several links to articles that compare electric and hydrogen vehicles. I will now fetch the content of these URLs to gather detailed data on energy production, vehicle lifecycle, and emissions.
Using tool: url_crawl_tool
(0:25) Thought: The error in fetching the URLs indicates that the input format was incorrect. I need to ensure the URLs are provided as a JSON array of strings. Let’s try again with the correct format.
Using tool: url_crawl_tool
Analysis of the Agent’s Thought Process:
Correctly interprets the comparison task and adapts to tool errors.
Snippet of Bot Output:
Environmental Impact Comparison Between Electric Vehicles (EVs) and Hydrogen-Powered Cars
Understanding the environmental impacts of EVs and hydrogen-powered cars requires a comprehensive analysis of energy production, vehicle lifecycle, and emissions. Below is a detailed comparison of these factors for both vehicle types.
1) Energy Production
Electric Vehicles (EVs):
Energy Source: EVs are powered by electricity, which can be generated from a variety of sources including renewable energy like solar, wind, or hydroelectric power, or from fossil fuels. The environmental impact largely depends on the energy mix of the grid. In regions with high renewable energy usage, EVs have a significantly lower carbon footprint.
Hydrogen-Powered Cars:
Energy Production: Hydrogen can be produced via:
Steam Methane Reforming (SMR): This method uses natural gas, which is not environmentally friendly due to CO2 emissions.
Electrolysis: Using renewable energy to split water into hydrogen and oxygen, which is clean but currently less common due to cost and energy efficiency issues.
Biomass Gasification: A potentially sustainable method but not yet widely implemented.
Time Taken: 1 minute and 10 seconds (from prompt to final answer)
Readability:
Flesch-Kincaid Grade Level: 17
Flesch-Kincaid Score: 17.08
Analysis of the Output:
Comprehensive Comparison: Covers energy production, vehicle lifecycle, and emissions.
Well-Structured: Clear headings and subheadings.
Accurate Information: Reflects current understanding of both technologies.
Minor Formatting Issues: Some inconsistencies.
Conclusion:
The agent delivers a thorough analysis despite tool errors and limited insight into its internal thought process.
Join our newsletter
Get latest tips, trends, and deals for free.
Task 5: Creative Writing
Prompt: Write a futuristic story (500 words) set in a world where electric vehicles have fully replaced traditional combustion-engine vehicles. Describe the environmental changes and societal impact.
Initial Task Understanding
(0:06) Thought: Write a futuristic story (500 words) set in a world where electric vehicles have fully replaced traditional combustion-engine vehicles. Describe the environmental changes and societal impact.
Creative and Descriptive: Vivid, imaginative, and engaging narrative.
Covers Key Aspects: Environmental and societal changes addressed.
Well-Structured: Clear beginning, development, and conclusion.
Word Count: 475 words (close to target).
Readability: Moderate complexity, suitable for the piece.
Snippet of Bot Output:
In the year 2050, the world had undergone a remarkable transformation as electric vehicles had become the primary mode of transportation in every corner of the globe. The once polluted skies now shimmered with clarity, and the streets hummed with the quiet whirring of electric motors. As the last gas-guzzling cars faded into memory, a new era of sustainable mobility and innovation dawned.
The environmental changes were profound. Gone were the days of smog-choked cities and oil spills despoiling pristine landscapes. The air was fresher, the water cleaner, and the natural world began to heal from decades of human-induced damage. With reduced emissions and a shift towards renewable energy sources to power these vehicles, the planet was on a path towards rejuvenation.
Time Taken: 10 seconds
Conclusion:
The agent delivers a strong, engaging story that fulfills all requirements within the specified constraints.
Final Thoughts
Our exploration of Llama 3.2 1B’s performance across diverse tasks provides a compelling snapshot of its capabilities as a compact yet potent AI agent. Despite the constraints of the video format, which offered limited visibility into the agent’s internal thought processes, the quality of its outputs consistently demonstrated its effectiveness and potential.
From generating a comprehensive article on project management fundamentals to accurately tackling complex calculations (though with a hiccup in explaining the final steps of the revenue increase problem), Llama 3.2 1B showcased its versatility. The summarization task highlighted its ability to distill key information concisely, while the comparison task, despite encountering a technical error, ultimately delivered a thorough analysis of the environmental impacts of different vehicle types. The agent’s foray into creative writing further cemented its proficiency, crafting an engaging narrative within the specified parameters.
However, the recurring theme of limited insight into the agent’s “thoughts” was also present in this series of tests. Similar to the previous agent analysis, we were often left with only a single thought per task, primarily reflecting the initial understanding of the prompt. This, coupled with repetitive thoughts, particularly during the comparison task, suggests potential areas for improvement in either the agent’s internal processes or the way its reasoning is visualized. It is important to note that the agent experienced issues with its tools during the comparison task and that this is likely related to the agent’s inability to provide a full response in this turn.
Nevertheless, Llama 3.2 1B’s performance remains impressive. Its ability to generate high-quality content, perform calculations, summarize information, and engage in creative writing highlights its potential as a powerful tool across various applications. This compact model demonstrates that significant capabilities can be packed into smaller AI architectures, opening up possibilities for more efficient and accessible AI solutions. While a deeper understanding of its internal workings would undoubtedly enhance our appreciation of its abilities, this hands-on evaluation confirms that Llama 3.2 1B is a force to be reckoned with in the evolving landscape of AI agents. As this technology continues to advance, it will be fascinating to see how these smaller models are further optimized and deployed in real-world scenarios.
Frequently asked questions
Llama 3.2 1B stands out for its compact yet powerful architecture, efficiently processing information and reasoning through diverse, real-world tasks, including content generation, calculation, summarization, and creative writing.
It employs strategic tool selection, iterative research, and adaptability to tackle tasks such as project management content, sales calculations, environmental comparisons, and creative storytelling, demonstrating logical reasoning and versatility.
Llama 3.2 1B excels at generating organized and high-quality content across scenarios, but sometimes its internal thought process is opaque, and it may encounter challenges with detailed calculations or tool integration.
Yes, its versatility in problem-solving, summarization, and content creation makes it valuable for business, education, and creative applications, especially when integrated through platforms like FlowHunt.
Arshia is an AI Workflow Engineer at FlowHunt. With a background in computer science and a passion for AI, he specializes in creating efficient workflows that integrate AI tools into everyday tasks, enhancing productivity and creativity.
Arshia Kahani
AI Workflow Engineer
Try FlowHunt’s AI Agents Today
Discover how autonomous AI agents like Llama 3.2 1B can transform your workflows, enhance decision-making, and unlock creative solutions.
AI Agents: Understanding the Thinking of Llama 3.2 3B
Explore the advanced capabilities of the Llama 3.2 3B AI Agent. This deep dive reveals how it goes beyond text generation, showcasing its reasoning, problem-sol...
Inside the Mind of Llama 3.3 70B Versatile 128k As an AI Agent
Explore the advanced capabilities of Llama 3.3 70B Versatile 128k as an AI Agent. This in-depth review examines its reasoning, problem-solving, and creative ski...
Explore the advanced capabilities of the Claude 3 AI Agent. This in-depth analysis reveals how Claude 3 goes beyond text generation, showcasing its reasoning, p...
9 min read
Claude 3
AI Agents
+5
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.