
The most significant setback of large language models is their tendency to present vague, outdated, or downright false information. To ensure the answers are always up to date and relevant to your use case, generative models need to be pointed to the right knowledge sources.
This approach, called the Retrieval-Augmented Generation (RAG), supplies generative models with your own knowledge sources. The retriever components, including the Document Retriever, allow you to use this method.
What is the Document Retriever component?
This component allows the chatbot to retrieve knowledge from your own sources, ensuring that the information is relevant, reliable, and up-to-date. This information comes directly from the sources you specified in the Documents and Schedules. The role of this component is to control the retrieval.
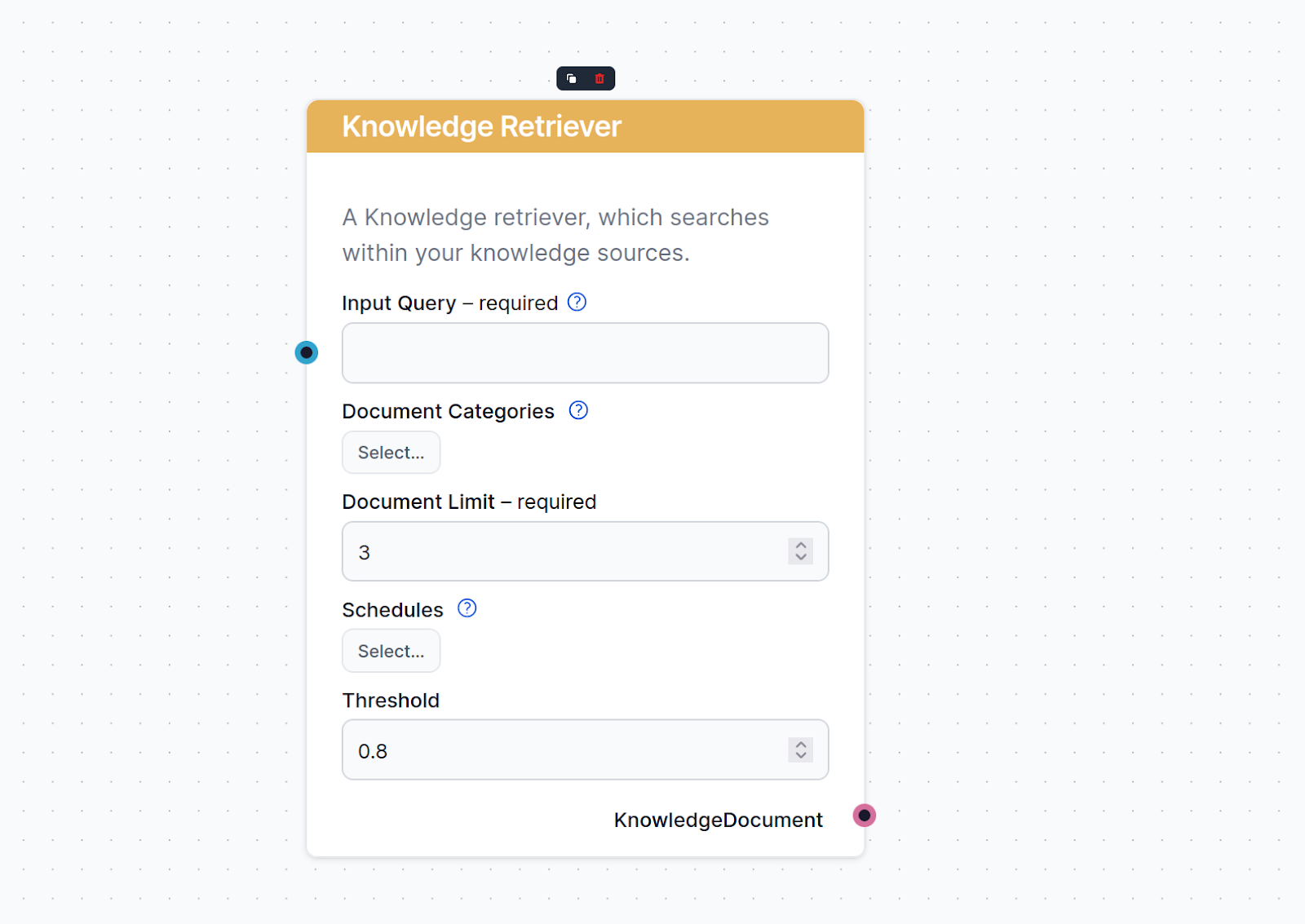
Input Query
Specifies the query that’s used to look up relevant information. It can either be linked from a component or inputted manually. In most cases, your input query will be the Chat Input.
Document Count
This setting limits the amount of documents the flow should retrieve from, making sure the results remain relevant and don’t take too long to generate.
Document categories
This optional setting lets you limit the retrieval to one of the categories you’ve created in the Documents screen of Knowledge Sources.
Schedules
Lets you limit the retrieval to one of the Schedules you’ve specified in the Schedules screen of Knowledge Sources.
Threshold
The sources in your knowledge database will match the query to varying degrees. AI will rank these by relevance from 0 to 1. This setting lets you control how well the output must match the query.
The exact threshold depends on your use case, but generally, 0.7-0.8 is recommended for highly relevant answers from a reasonable amount of sources.
Imagine you set the threshold to 0.6 and have the following articles:
- Article A: 0.8
- Article B: 0.65
- Article C: 0.5
- Article D: 0.9
Only the articles with a relevance score of over 0.6 will make it into the output, that is, only A, B, and D.
- A high threshold, such as 0.9, will return very relevant results that closely match the query, but it might struggle to find enough documents and miss some relevant ones.
- A low threshold, for example, one below 0.5, will provide information from more documents, but it runs the risk of returning irrelevant information.
How to connect the Document Retriever component to your flow
The component contains just one input and one output handle:
- Input Query: The query can be any text output. Common use cases would be connecting human Chat Input or a Generator.
- Output: The output of any retriever-type component is always a Document.
The Document output contains structured data unsuitable for the final chat output. All components that take Documents as their input transform them into a user-friendly format. These are either Widget components or the Document to Text transformer.
Example
Let’s try it out! Before building the flow, we must ensure we have created relevant Documents or Schedules. If no good source is present, the chatbot will either apologize for being unable to answer or resort to hallucinating an answer.
- As always, start with Chat Input.
- Now add the Document Retriever and connect Chat Input as the Input Query.
- The output is a Document that needs to be transformed; for this example, we will use the Document to Text.
- Next, connect an AI Generator.
- You’re ready to chat.
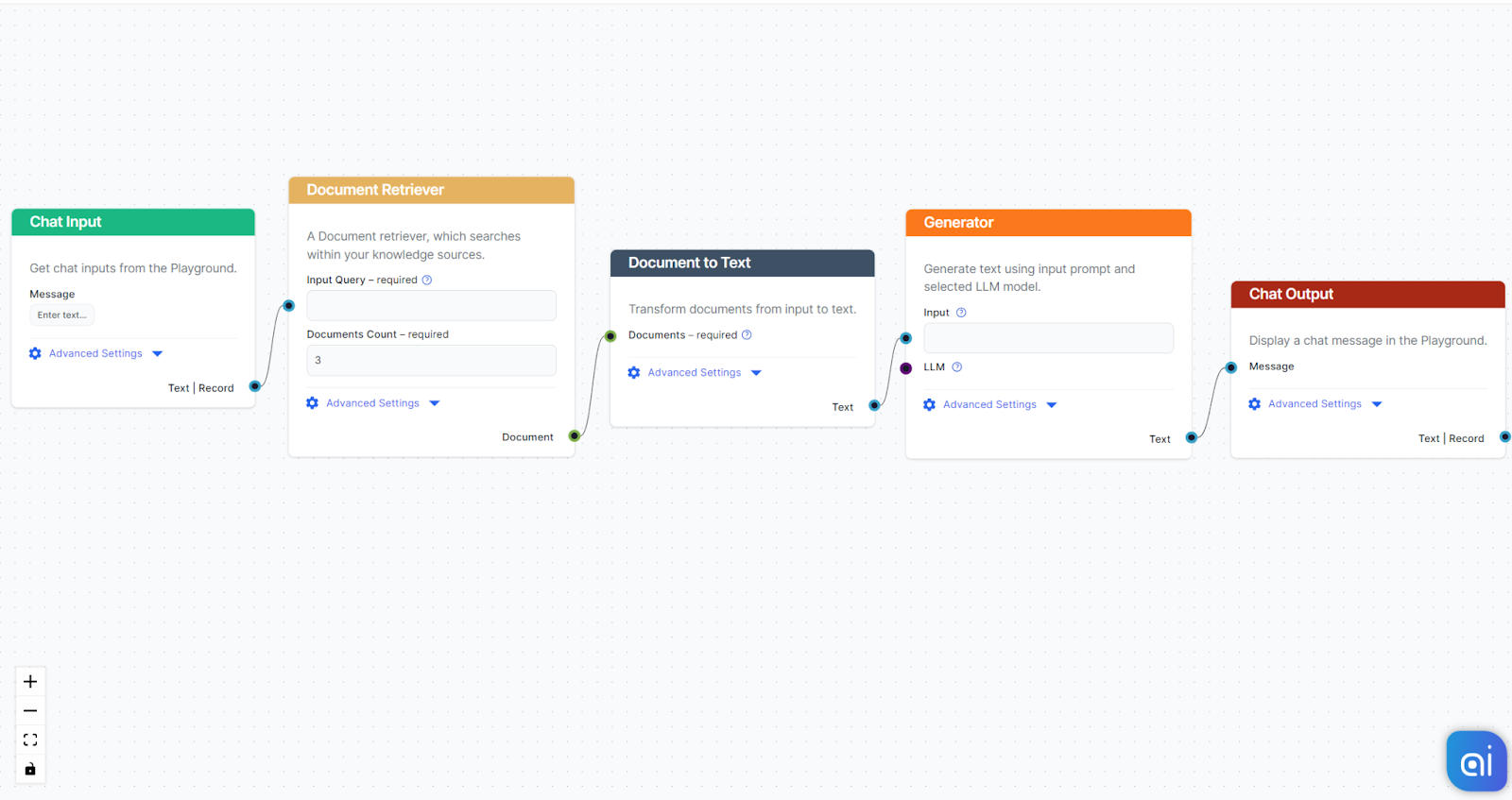
Now our Flow can search our sources based on a human query, transform the structured data into readable text, and pass it to AI to generate a user-friendly answer.
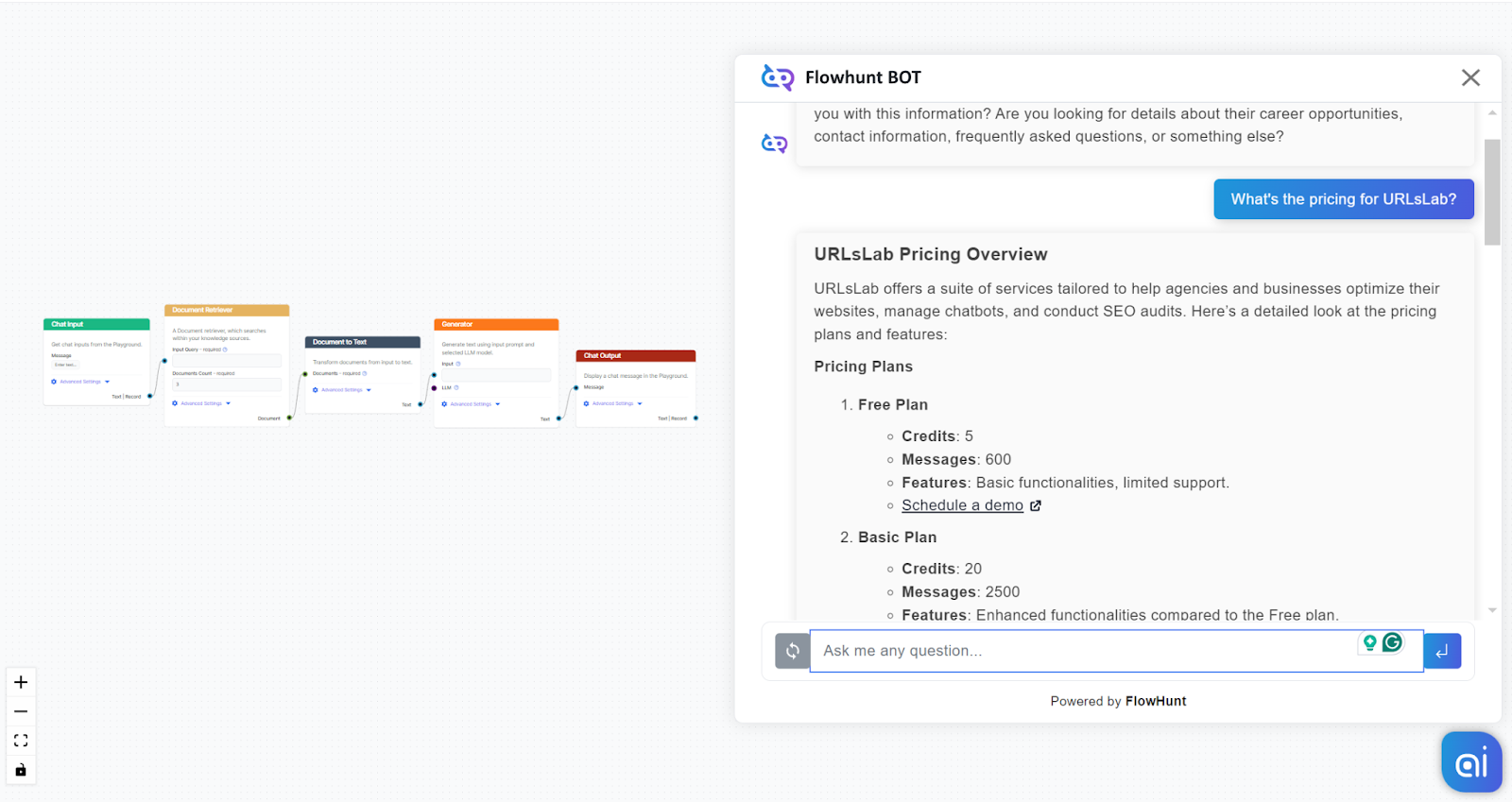
Our Knowledge Sources contain a Schedule set to crawl URLsLab’s pricing page for up-to-date information. Let’s ask the bot about it:
What happens without a Retriever connected?
We got the correct and nicely structured information. How do we know we got the right information only thanks to the Retriever?
If you ask ChatGPT-4o about the information, it will search the web and return outdated information from various websites or hallucinate an answer altogether. An older model simply could not answer, as the product is too new for it to know, or it would resort to hallucinating an answer.
There’s always a chance AI may provide the right answers on its own, but connecting a fresh and accurate source of information ensures it does so consistently.
Frequently Asked Questions
What is the Knowledge Retriever component?
This component allows the Flow to retrieve knowledge from your own sources, such as documents and URLs, ensuring the returned information is relevant, reliable, and up-to-date.
Why can’t I connect a Document Retriever to Chat Output?
Retriever components create structured data that is not suitable for output. That’s why it must first be transformed. To do this, either transform it to text or use a Widget-type component to make it visually pleasing. Only then can you happily send the text output to the Chat Output component and know the answer will be relevant and well-structured.
Where does the Knowledge Retriever get information from?
The component searches for the closest query match within the information from user-specified URLs, documents, and schedules.
Why can’t I connect the Knowledge Retriever to Chat Output?
The component does not output the information in text form. The output of Knowledge Retriever is a Knowledge Document. This more structured document includes data unsuitable for the final answer. That’s why you must first transform the document to text form via the Knowledge to Text component to gain a reader-friendly text output.
Can I connect both the Document Retriever and GoogleSearch? If so, which one is prioritized?
You can use both simultaneously to make the results more relevant. Each retriever would lead to its own output. In this case, the priority is set by the order of outputs in the canvas. This means that if Document Retriever is the first output from the top, it will be prioritized over other retrievers.



