AI can analyze large quantities of data in seconds, but only some of the data will be relevant or suitable for output. The Document to Text component gives you control over how the data from retrievers is processed and transformed into text.
What is the Document to Text component?
This component transforms the structured data from Retrievers into readable markdown text that the bot can use to craft an answer. It also dictates how the data should be processed, which data is prioritized, and which is left out.
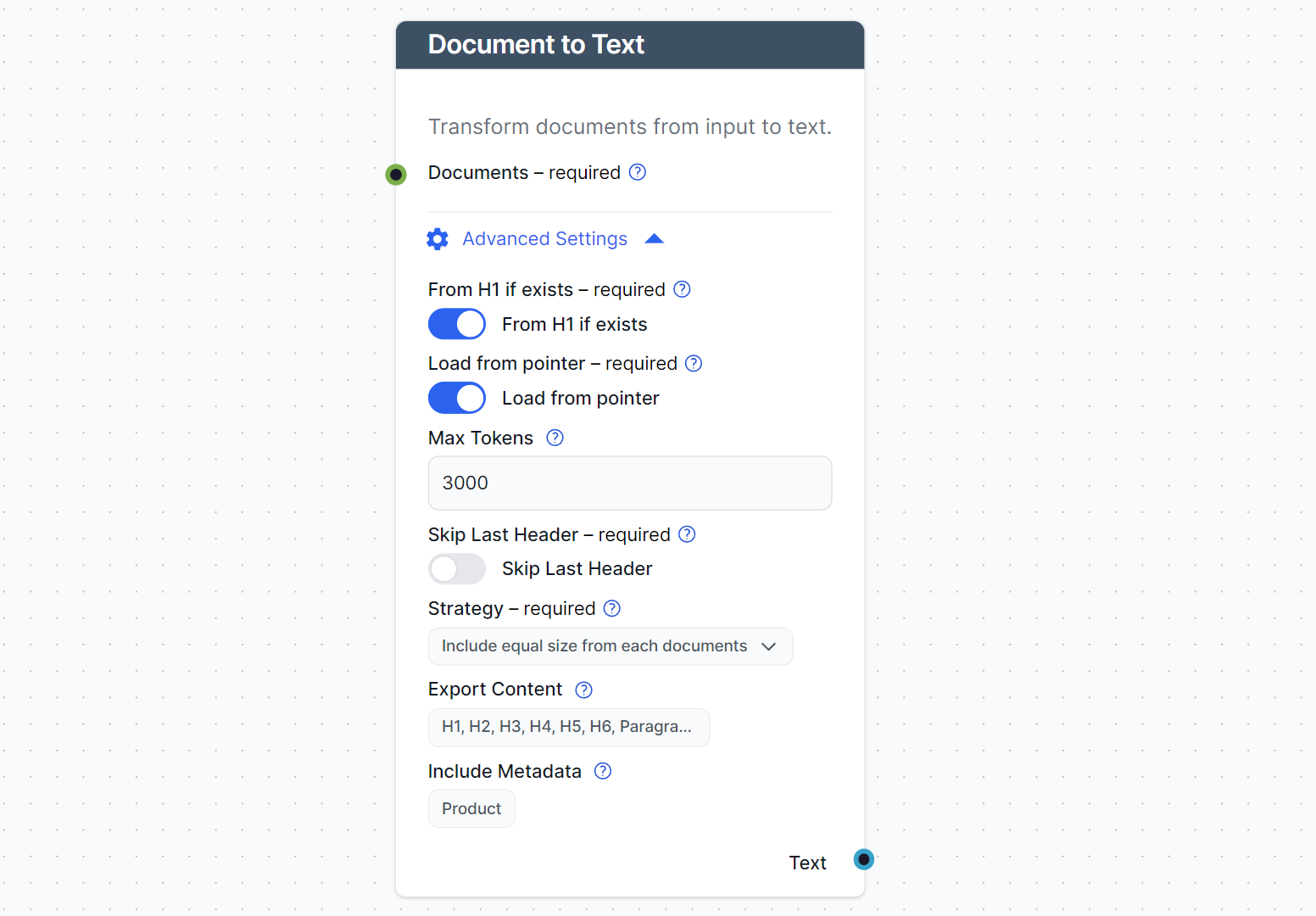
This component comes with settings that give you control over the resulting text output. These settings include:
Limiting the output
- Load from pointer: When grabbing knowledge from a particular article, this setting allows you to control whether you only want the exact part of the article related to the query or the whole article to be loaded.
- Skip the last Heading: The last heading of an article is often the conclusion, the FAQ section, or even the author bio. These are often unnecessary and may even harm the results.
- Use Metadata: Allows utilization of metadata in the text output.
Max Tokens
Tokens are the fundamental units AI uses to process, analyze, and retrieve information from documents during crawling. The Max Tokens setting limits the total number of tokens used to perform these tasks. This setting ensures the process doesn’t get too pricey or take too long.
Strategy
The bot may crawl many documents to create the text output. The Strategy setting lets you control how it utilizes these documents smartly while staying within the token limit.
Currently, there are two possible strategies:
- Include equal size from each document: Utilizes all found documents equally.
- Concat documents, fill from first up to token limit: Links the documents together while prioritizing them by relevance to the query.
How to connect the Document to Text component to your flow
This is a transformer component, meaning it bridges the gap between two outputs. Document to Text takes Documents outputted by the Retriever components:
- Document Retriever – gets knowledge from connected knowledge sources (pages, documents, etc.).
- URL Retriever – Allows you to specify a URL from which the bot should get knowledge.
- GoogleSearch – Gives the bot the ability to search the web for knowledge.
The knowledge is converted into readable Markdown text as it passes through the transformer. This text can then be connected to components requiring text input, such as splitters, widgets, or outputs.
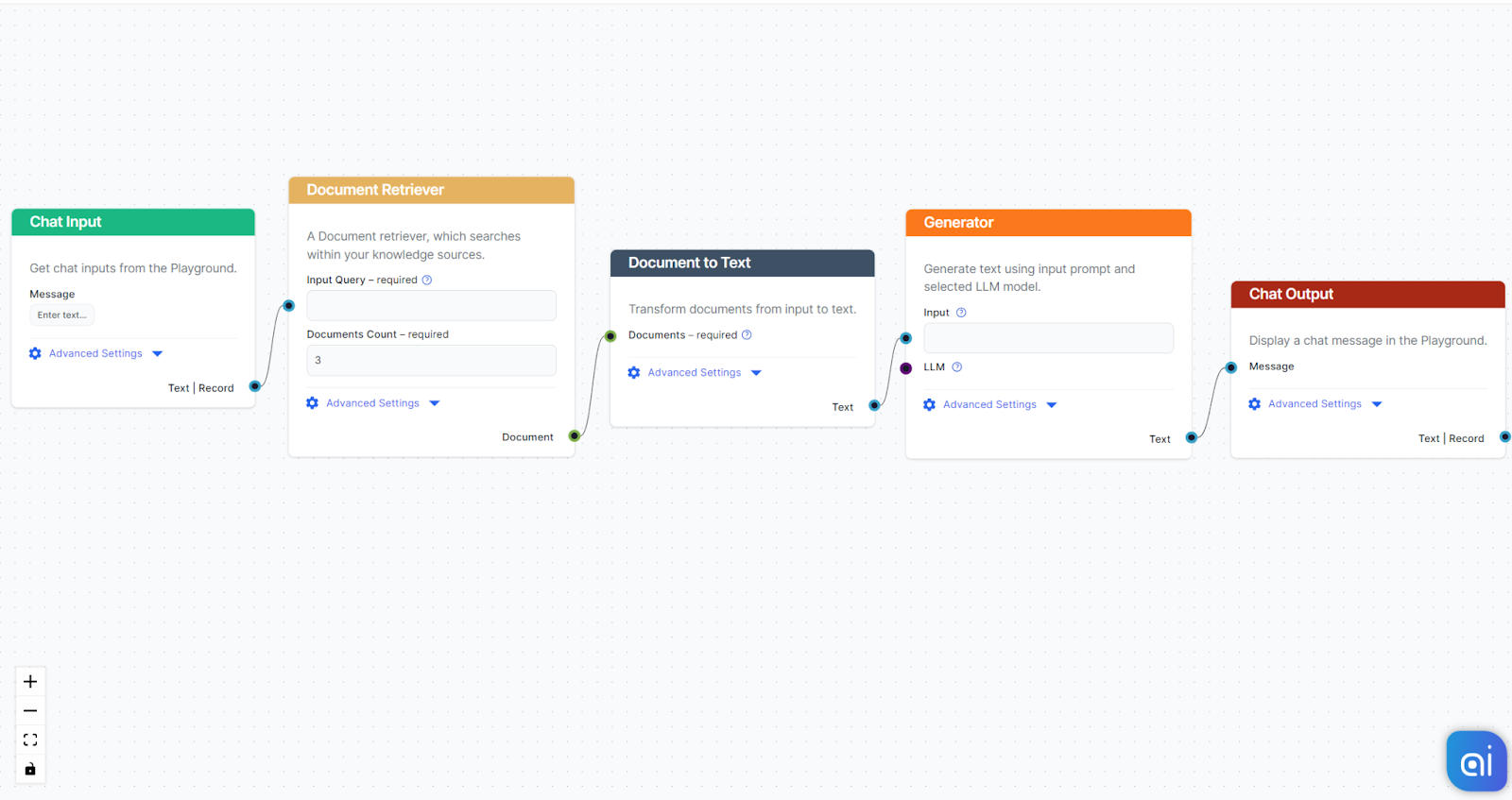
Here is an example flow using the Document to Text component to bridge the gap between the Document Retrievers and the AI Generator:
Frequently Asked Questions
What is the Document to Text component?
The component grabs knowledge from retriever-type components and transforms it into readable markdown text, which can then be connected to any component that takes text as input.


Text to Image Prompt Generator from URL
Transform URLs into AI image prompts with FlowHunt. Visualize content, enhance creativity, and boost engagement effortlessly!