
Reduce AI Hallucinations By Adding Custom Knowledgebases
Reduce AI hallucinations and ensure accurate chatbot responses by using FlowHunt's Schedule feature. Discover the benefits, practical use cases, and step-by-ste...
8 min read
AI
Chatbot
+4
No matter how powerful, AI is still just a machine that relays the information it learns. It doesn’t understand jokes, hypotheticals, or sarcasm, which are often to blame for the most hilariously awful (and sometimes seriously harmful) answers. To ensure your Chatbot doesn’t create the newest AI scandal and to help it understand your content better, you can let it know which content to skip.
The way to ensure AI’s reliability is by monitoring the information it learns from. Not all of your content will be suitable for the Chatbot to use. The flowhunt-skip class allows you to mark the content FlowHunt should not index. Any HTML element with this class will be ignored while processing the content.
There are two main reasons you should use this class, but feel free to use it on any content you find unnecessary or inappropriate for the bot to use.
Skipping repetitive content: If similar content keeps getting indexed, it makes it hard for AI to distinguish and categorize what the content is about. Skipping duplicit information also saves you money on text processing in the long run.
Skipping risky or inappropriate information: You should skip any information that may cause the AI to give wrong, harmful, or out-of-context answers. Be especially cautious if your brand tone often uses jokes or strong language. While great for other content, the users might not appreciate a snarky bot.
FlowHunt crawls and indexes your website to give context to the Chatbot. Anything FlowHunt indexes your Chatbot may use at some point.
Adding the flowhunt-skip class to HTML elements lets you mark the content you don’t want to index. Any element featuring this class will be ignored and never reach the Chatbot.
Here’s an example of using the class:
<div class="flowhunt-skip">
<h2>Duplicit content</h2>
<p>This content is duplicate. I don’t want FlowHunt to index it again.</p>
</div>
You can also skip just a single paragraph or a part of one element:
<div>
<h2>My content</h2>
<p>This paragraph should be indexed.</p>
<p class="flowhunt-skip">I don't want the Chatbot to use this information.</p>
<p>This paragraph should be indexed.</p>
</div>
Start your free trial today and see results within days.
The crawling process runs in the background and is based on the schedules you set up. It only downloads the HTML page. Any images or media simply get stored as links. Any redirects are followed, and canonical URLs are evaluated.
Once crawled, the HTML content gets converted into plain markdown text. Some information may be removed during this process. The final markdown text is offered to the Chatbot as context. The bot can then retrieve this information whenever needed.
The markdown text gets split into chunks, vectorized, and stored in a vector database. This type of database assigns values to word meanings. As a result, AI can understand related words instead of needing an exact word match.
The words get spread on a grid based on their assigned values. This allows the computer to understand which words are close in meaning to each other:
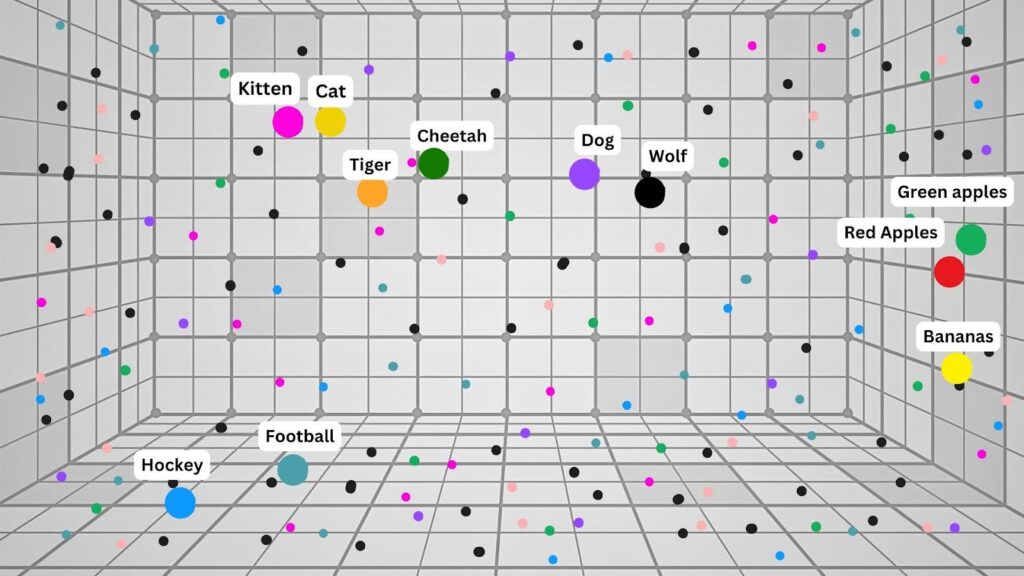
Note: This is a very simplified model. In practice, AI does this with thousands of words, phrases, and entire sentences.
The retrieval of information from vector databases is called the semantic search. It’s the AI’s ability to search and evaluate the meaning of words in the vector database, using them to provide answers.
When a user posts a query, the bot converts the words to vectors. It then searches the database for any close matches from your content. Finding matches or similar content, it then uses the information to craft an answer.
Get latest tips, trends, and deals for free.
Imagine you own an online pet shop. A customer asks the following query:
“Do you sell food for kittens?”
You do, but the product name features the word “junior” instead of “kitten”. The bot will be able to understand that “junior cat food” is the same (or very similar) as “food for kittens” and successfully guide the customer to the right product.
Without semantic search in the vector database, the Chatbot would simply reply that you don’t carry “food for kittens,” making you lose a future customer. You don’t have to worry about anything like this happening when using FlowHunt.
Smart Chatbots and AI tools under one roof. Connect intuitive blocks to turn your ideas into automated Flows.
Reduce AI hallucinations and ensure accurate chatbot responses by using FlowHunt's Schedule feature. Discover the benefits, practical use cases, and step-by-ste...

Kick the writer's block and get tailored content ideas. Learn how to build your own custom AI Content Idea Generator with FlowHunt, generating unique, trending ...

Integrate FlowHunt with Scrapling Fetch MCP to enable AI-powered agents to securely retrieve text content from websites, bypass advanced bot detection, and extr...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.