Information Retrieval
Information Retrieval leverages AI, NLP, and machine learning to efficiently and accurately retrieve data that meets user requirements. Foundational for web sea...
6 min read
Information Retrieval
AI
+4

AI Search is a semantic or vector-based search methodology that uses machine learning models to understand the intent and contextual meaning behind search queries, delivering more relevant and accurate results than traditional keyword-based search.
AI Search uses machine learning to understand the context and intent of search queries, transforming them into numerical vectors for more accurate results. Unlike traditional keyword searches, AI Search interprets semantic relationships, making it effective for diverse data types and languages.
AI Search, often referred to as semantic or vector search, is a search methodology that leverages machine learning models to understand the intent and contextual meaning behind search queries. Unlike traditional keyword-based search, AI search transforms data and queries into numerical representations known as vectors or embeddings. This allows the search engine to comprehend the semantic relationships between different pieces of data, providing more relevant and accurate results even when exact keywords are not present.
AI Search represents a significant evolution in search technologies. Traditional search engines rely heavily on keyword matching, where the presence of specific terms in both the query and documents determines relevance. AI Search, however, utilizes machine learning models to grasp the underlying context and meaning of queries and data.
By converting text, images, audio, and other unstructured data into high-dimensional vectors, AI Search can measure the similarity between different pieces of content. This approach enables the search engine to deliver results that are contextually relevant, even if they don’t contain the exact keywords used in the search query.
Key Components:
At the heart of AI Search lies the concept of vector embeddings. Vector embeddings are numerical representations of data that capture the semantic meaning of text, images, or other data types. These embeddings position similar pieces of data close to each other in a multi-dimensional vector space.
How It Works:
Example:
Start your free trial today and see results within days.
Traditional keyword-based search engines operate by matching terms in the search query with documents containing those terms. They rely on techniques like inverted indexes and term frequency to rank results.
Limitations of Keyword-Based Search:
AI Search Advantages:
| Aspect | Keyword-Based Search | AI Search (Semantic/Vector) |
|---|---|---|
| Matching | Exact keyword matches | Semantic similarity |
| Context Awareness | Limited | High |
| Handling Synonyms | Requires manual synonym lists | Automatic through embeddings |
| Misspellings | May fail without fuzzy search | More tolerant due to semantic context |
| Understanding Intent | Minimal | Significant |
Semantic Search is a core application of AI Search that focuses on understanding the user’s intent and the contextual meaning of queries.
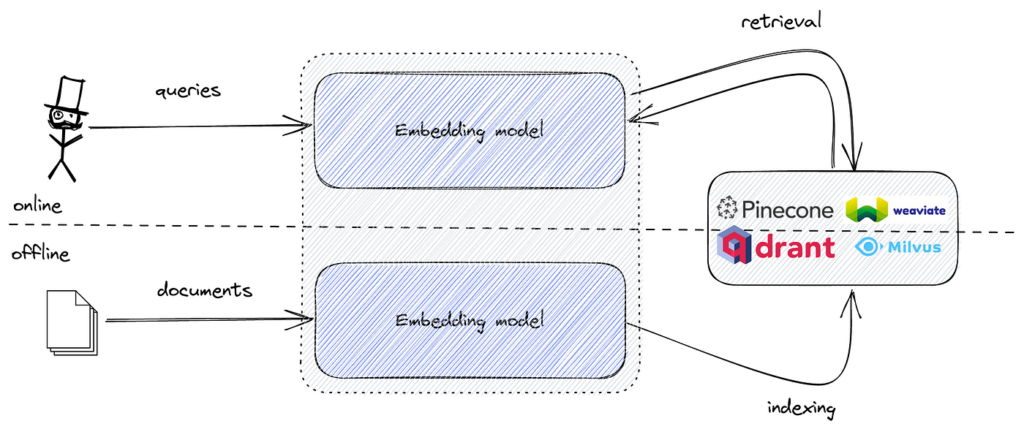
Process:
Key Techniques:
Get latest tips, trends, and deals for free.
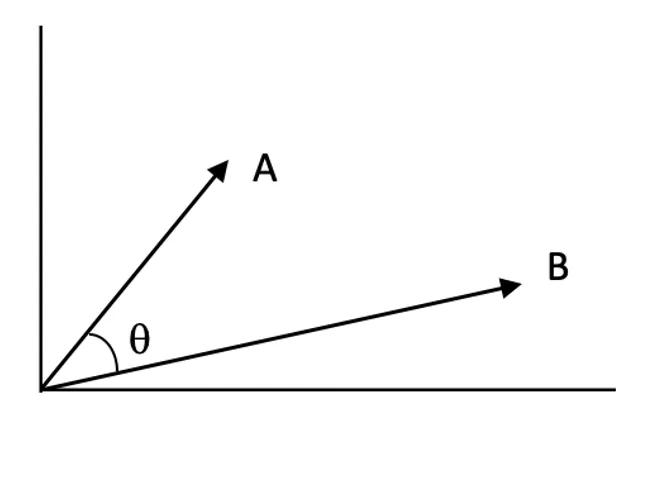
Similarity Scores:
Similarity scores quantify how closely related two vectors are in the vector space. A higher score indicates higher relevance between the query and a document.
Approximate Nearest Neighbor (ANN) Algorithms:
Finding exact nearest neighbors in high-dimensional spaces is computationally intensive. ANN algorithms provide efficient approximations.
AI Search opens up a wide range of applications across various industries due to its ability to understand and interpret data beyond simple keyword matching.
Description: Semantic Search enhances user experience by interpreting the intent behind queries and providing contextually relevant results.
Examples:
Description: By understanding user preferences and behavior, AI Search can provide personalized content or product recommendations.
Examples:
Description: AI Search enables systems to understand and answer user queries with precise information extracted from documents.
Examples:
Description: AI Search can index and search through unstructured data types such as images, audio, and videos by converting them into embeddings.
Examples:
Integrating AI Search into AI automation and chatbots significantly enhances their capabilities.
Benefits:
Implementation Steps:
Use Case Example:
While AI Search offers numerous advantages, there are challenges to consider:
Mitigation Strategies:
Semantic and vector search in AI have emerged as powerful alternatives to traditional keyword-based and fuzzy searches, significantly enhancing the relevance and accuracy of search results by understanding the context and meaning behind queries.
When implementing semantic search, textual data is converted into vector embeddings that capture the semantic meaning of the text. These embeddings are high-dimensional numerical representations. To search through these embeddings efficiently and find the most similar ones to a query embedding, we need a tool optimized for similarity search in high-dimensional spaces.
FAISS provides the necessary algorithms and data structures to perform this task efficiently. By combining semantic embeddings with FAISS, we can create a powerful semantic search engine capable of handling large datasets with low latency.
Implementing semantic search with FAISS in Python involves several steps:
Let’s delve into each step in detail.
Prepare your dataset (e.g., articles, support tickets, product descriptions).
Example:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
Clean and format the text data as needed.
Convert the textual data into vector embeddings using pre-trained Transformer models from libraries like Hugging Face (transformers or sentence-transformers).
Example:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained model
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Generate embeddings for all documents
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 as required by FAISS.Create a FAISS index to store the embeddings and enable efficient similarity search.
Example:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 performs brute-force search using L2 (Euclidean) distance.Convert the user’s query into an embedding and find the nearest neighbors.
Example:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Use the indices to display the most relevant documents.
Example:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
Expected Output:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS provides several types of indices:
Using an Inverted File Index (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalization and Inner Product Search:
Using cosine similarity can be more effective for textual data
AI Search is a modern search methodology that uses machine learning and vector embeddings to understand the intent and contextual meaning of queries, delivering more accurate and relevant results than traditional keyword-based search.
Unlike keyword-based search, which relies on exact matches, AI Search interprets the semantic relationships and intent behind queries, making it effective for natural language and ambiguous inputs.
Vector embeddings are numerical representations of text, images, or other data types that capture their semantic meaning, enabling the search engine to measure similarity and context between different pieces of data.
AI Search powers semantic search in e-commerce, personalized recommendations in streaming, question-answering systems in customer support, unstructured data browsing, and document retrieval in research and enterprise.
Popular tools include FAISS for efficient vector similarity search, and vector databases like Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch, and Pgvector for scalable storage and retrieval of embeddings.
By integrating AI Search, chatbots and automation systems can understand user queries more deeply, retrieve contextually relevant answers, and deliver dynamic, personalized responses.
Challenges include high computational requirements, complexity in model interpretability, need for high-quality data, and ensuring privacy and security with sensitive information.
FAISS is an open-source library for efficient similarity search on high-dimensional vector embeddings, widely used to build semantic search engines that can handle large-scale datasets.
Discover how AI-powered semantic search can transform your information retrieval, chatbots, and automation workflows.
Information Retrieval leverages AI, NLP, and machine learning to efficiently and accurately retrieve data that meets user requirements. Foundational for web sea...
Discover what an Insight Engine is—an advanced, AI-driven platform that enhances data search and analysis by understanding context and intent. Learn how Insight...
Discover what Perplexity AI is, how it works, and how it compares to ChatGPT. Learn about real-time search, source citations, and advanced AI features in our co...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.