
MLflow
MLflow is an open-source platform designed to streamline and manage the machine learning (ML) lifecycle. It provides tools for experiment tracking, code packagi...
6 min read
MLflow
Machine Learning
+3
Kubeflow is an open-source machine learning (ML) platform on Kubernetes, simplifying the deployment, management, and scaling of ML workflows. It offers a suite of tools covering the entire ML lifecycle, from model development to deployment and monitoring, enhancing scalability, reproducibility, and resource utilization.
Kubeflow’s mission is to make the scaling of ML models and their deployment to production as simple as possible by utilizing Kubernetes’ capabilities. This includes easy, repeatable, and portable deployments across diverse infrastructures. The platform began as a method for running TensorFlow jobs on Kubernetes and has since evolved into a versatile framework supporting a wide range of ML frameworks and tools.
Kubeflow Pipelines is a core component that allows users to define and execute ML workflows as Directed Acyclic Graphs (DAGs). It provides a platform for building portable and scalable machine learning workflows using Kubernetes. The Pipelines component consists of:
These features enable data scientists to automate the end-to-end process of data preprocessing, model training, evaluation, and deployment, promoting reproducibility and collaboration in ML projects. The platform supports the reuse of components and pipelines, thus streamlining the creation of ML solutions.
The Kubeflow Central Dashboard serves as the main interface for accessing Kubeflow and its ecosystem. It aggregates the user interfaces of various tools and services within the cluster, providing a unified access point for managing machine learning activities. The dashboard offers functionalities such as user authentication, multi-user isolation, and resource management.
Kubeflow integrates with Jupyter Notebooks, offering an interactive environment for data exploration, experimentation, and model development. Notebooks support various programming languages and allow users to create and execute ML workflows collaboratively.
Kubeflow Metadata is a centralized repository for tracking and managing metadata associated with ML experiments, runs, and artifacts. It ensures reproducibility, collaboration, and governance across ML projects by providing a consistent view of ML metadata.
Katib is a component for automated machine learning (AutoML) within Kubeflow. It supports hyperparameter tuning, early stopping, and neural architecture search, optimizing the performance of ML models by automating the search for optimal hyperparameters.
Kubeflow is used by organizations across various industries to streamline their ML operations. Some common use cases include:
Spotify utilizes Kubeflow to empower its data scientists and engineers in developing and deploying machine learning models at scale. By integrating Kubeflow with their existing infrastructure, Spotify has streamlined its ML workflows, reducing time-to-market for new features and improving the efficiency of its recommendation systems.
Start your free trial today and see results within days.
Kubeflow allows organizations to scale their ML workflows up or down as needed and deploy them across various infrastructures, including on-premises, cloud, and hybrid environments. This flexibility helps avoid vendor lock-in and enables seamless transitions between different computing environments.
Kubeflow’s component-based architecture facilitates the reproduction of experiments and models. It provides tools for versioning and tracking datasets, code, and model parameters, ensuring consistency and collaboration among data scientists.
Kubeflow is designed to be extensible, allowing integration with various other tools and services, including cloud-based ML platforms. Organizations can customize Kubeflow with additional components, leveraging existing tools and workflows to enhance their ML ecosystem.
By automating many tasks associated with deploying and managing ML workflows, Kubeflow frees up data scientists and engineers to focus on higher-value tasks, such as model development and optimization, leading to gains in productivity and efficiency.
Kubeflow’s integration with Kubernetes allows for more efficient resource utilization, optimizing hardware resource allocation and reducing costs associated with running ML workloads.
To start using Kubeflow, users can deploy it on a Kubernetes cluster, either on-premises or in the cloud. Various installation guides are available, catering to different levels of expertise and infrastructure requirements. For those new to Kubernetes, managed services like Vertex AI Pipelines offer a more accessible entry point, handling infrastructure management and allowing users to focus on building and running ML workflows.
This detailed exploration of Kubeflow provides insights into its functionalities, benefits, and use cases, offering a comprehensive understanding for organizations looking to enhance their machine learning capabilities.
Get latest tips, trends, and deals for free.
Kubeflow is an open-source project designed to facilitate the deployment, orchestration, and management of machine learning models on Kubernetes. It provides a comprehensive end-to-end stack for machine learning workflows, making it easier for data scientists and engineers to build, deploy, and manage scalable machine learning models.
Deployment of ML Models using Kubeflow on Different Cloud Providers
Authors: Aditya Pandey et al. (2022)
This paper explores the deployment of machine learning models using Kubeflow on various cloud platforms. The study provides insights into the setup process, deployment models, and performance metrics of Kubeflow, serving as a useful guide for beginners. The authors highlight the tool’s features and limitations and demonstrate its use in creating end-to-end machine learning pipelines. The paper aims to assist users with minimal Kubernetes experience in leveraging Kubeflow for model deployment.
Read more
CLAIMED, a visual and scalable component library for Trusted AI
Authors: Romeo Kienzler and Ivan Nesic (2021)
This work focuses on the integration of trusted AI components with Kubeflow. It addresses concerns such as explainability, robustness, and fairness in AI models. The paper introduces CLAIMED, a reusable component framework that incorporates tools like AI Explainability360 and AI Fairness360 into Kubeflow pipelines. This integration facilitates the development of production-grade machine learning applications using visual editors like ElyraAI.
Read more
Jet energy calibration with deep learning as a Kubeflow pipeline
Authors: Daniel Holmberg et al. (2023)
Kubeflow is utilized to create a machine learning pipeline for calibrating jet energy measurements at the CMS experiment. The authors employ deep learning models to improve jet energy calibration, showcasing how Kubeflow’s capabilities can be extended to high-energy physics applications. The paper discusses the pipeline’s effectiveness in scaling hyperparameter tuning and serving models efficiently on cloud resources.
Read more
Discover how Kubeflow can simplify your machine learning workflows on Kubernetes, from scalable training to automated deployment.
MLflow is an open-source platform designed to streamline and manage the machine learning (ML) lifecycle. It provides tools for experiment tracking, code packagi...
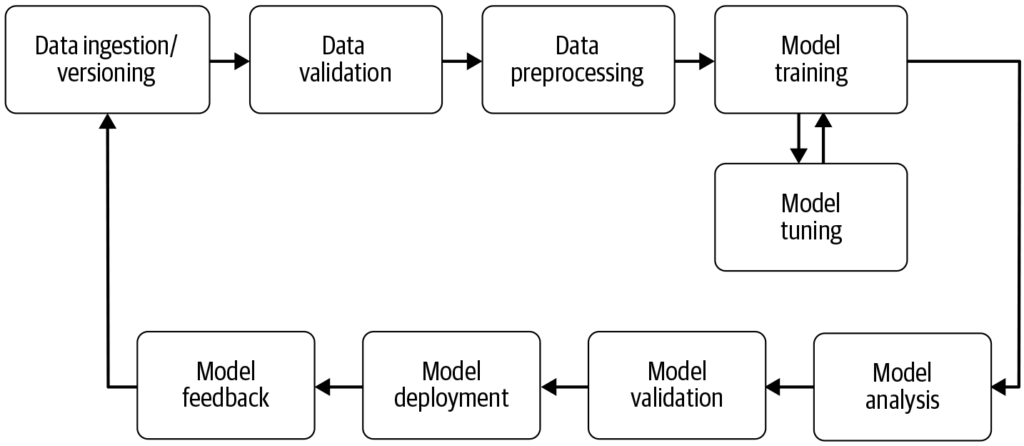
A machine learning pipeline is an automated workflow that streamlines and standardizes the development, training, evaluation, and deployment of machine learning...

Integrate FlowHunt with your Golang-based Model Context Protocol (MCP) server to automate Kubernetes resource management, streamline DevOps workflows, and lever...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.