Classifier
An AI classifier is a machine learning algorithm that assigns class labels to input data, categorizing information into predefined classes based on learned patt...
10 min read
AI
Classifier
+3
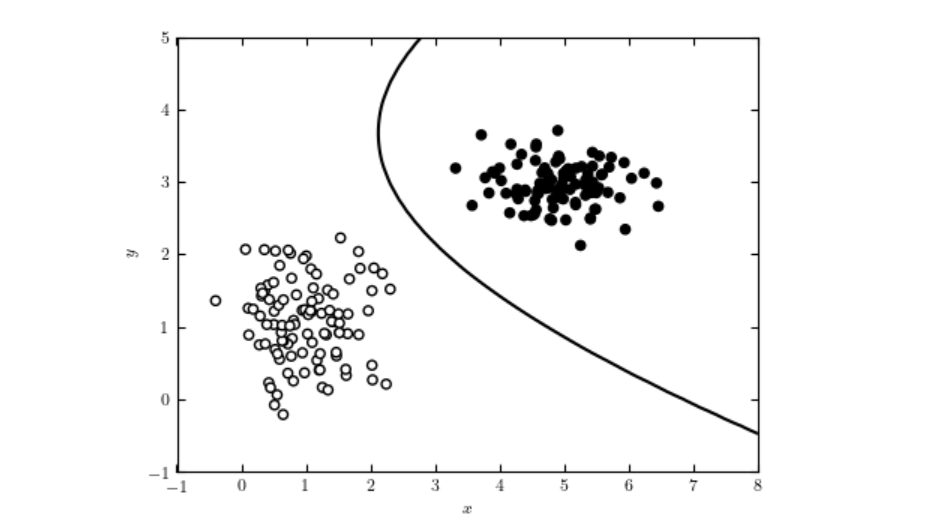
Naive Bayes is a family of classification algorithms based on Bayes’ Theorem, applying conditional probability with the simplifying assumption that features are conditionally independent. Despite this, Naive Bayes classifiers are effective, scalable, and used in applications like spam detection and text classification.
Naive Bayes is a family of simple, effective classification algorithms based on Bayes’ Theorem, assuming conditional independence among features. It’s widely used for spam detection, text classification, and more due to its simplicity and scalability.
Naive Bayes is a family of classification algorithms based on Bayes’ Theorem, which applies the principle of conditional probability. The term “naive” refers to the simplifying assumption that all features in a dataset are conditionally independent of each other given the class label. Despite this assumption often being violated in real-world data, Naive Bayes classifiers are recognized for their simplicity and effectiveness in various applications, such as text classification and spam detection.
Bayes’ Theorem
This theorem forms the foundation of Naive Bayes, providing a method to update the probability estimate of a hypothesis as more evidence or information becomes available. Mathematically, it is expressed as:
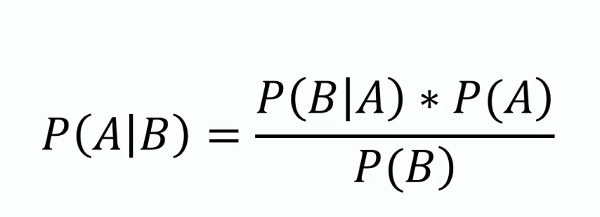
where ( P(A|B) ) is the posterior probability, ( P(B|A) ) is the likelihood, ( P(A) ) is the prior probability, and ( P(B) ) is the evidence.
Conditional Independence
The naive assumption that each feature is independent of every other feature given the class label. This assumption simplifies computation and allows the algorithm to scale well with large datasets.
Posterior Probability
The probability of the class label given the feature values, calculated using Bayes’ Theorem. This is the central component in making predictions with Naive Bayes.
Types of Naive Bayes Classifiers
Naive Bayes classifiers work by calculating the posterior probability for each class given a set of features and selecting the class with the highest posterior probability. The process involves the following steps:
Naive Bayes classifiers are particularly effective in the following applications:
Consider a spam filtering application using Naive Bayes. The training data consists of emails labeled as “spam” or “not spam”. Each email is represented by a set of features, such as the presence of specific words. During training, the algorithm calculates the probability of each word given the class label. For a new email, the algorithm computes the posterior probability for “spam” and “not spam” and assigns the label with the higher probability.
Naive Bayes classifiers can be integrated into AI systems and chatbots to enhance their natural language processing bridges human-computer interaction. Discover its key aspects, workings, and applications today!") capabilities. For instance, they can be used to detect the intent of user queries, classify texts into predefined categories, or filter inappropriate content. This functionality improves the interaction quality and relevance of AI-driven solutions. Additionally, the algorithm’s efficiency makes it suitable for real-time applications, an important consideration for AI automation and chatbot systems.
Naive Bayes is a family of simple yet powerful probabilistic algorithms based on applying Bayes’ theorem with strong independence assumptions between the features. It is widely used for classification tasks due to its simplicity and effectiveness. Here are some scientific papers that discuss various applications and improvements of the Naive Bayes classifier:
Improving spam filtering by combining Naive Bayes with simple k-nearest for classification and regression, learn its principles, distance metrics, and Python implementation.") neighbor searches
Author: Daniel Etzold
Published: November 30, 2003
This paper explores the use of Naive Bayes for email classification, highlighting its ease of implementation and efficiency. The study presents empirical results showing how combining Naive Bayes with k-nearest neighbor searches can enhance spam filter accuracy. The combination provided slight improvements in accuracy with a large number of features and significant improvements with fewer features. Read the paper
.
Locally Weighted Naive Bayes
Authors: Eibe Frank, Mark Hall, Bernhard Pfahringer
Published: October 19, 2012
This paper addresses the primary weakness of Naive Bayes, which is its assumption of attribute independence. It introduces a locally weighted version of Naive Bayes that learns local models at prediction time, thus relaxing the independence assumption. The experimental results demonstrate that this approach rarely degrades accuracy and often improves it significantly. The method is praised for its conceptual and computational simplicity compared to other techniques. Read the paper
.
Naive Bayes Entrapment Detection for Planetary Rovers
Author: Dicong Qiu
Published: January 31, 2018
In this study, the application of Naive Bayes classifiers for entrapment detection in planetary rovers is discussed. It defines the criteria for rover entrapment and demonstrates the use of Naive Bayes in detecting such scenarios. The paper details experiments conducted with AutoKrawler rovers, providing insights into the effectiveness of Naive Bayes for autonomous rescue procedures. Read the paper
.
Smart Chatbots and AI tools under one roof. Connect intuitive blocks to turn your ideas into automated Flows.
An AI classifier is a machine learning algorithm that assigns class labels to input data, categorizing information into predefined classes based on learned patt...
Text classification, also known as text categorization or text tagging, is a core NLP task that assigns predefined categories to text documents. It organizes an...
A Bayesian Network (BN) is a probabilistic graphical model that represents variables and their conditional dependencies via a Directed Acyclic Graph (DAG). Baye...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.