
Optical Character Recognition (OCR)
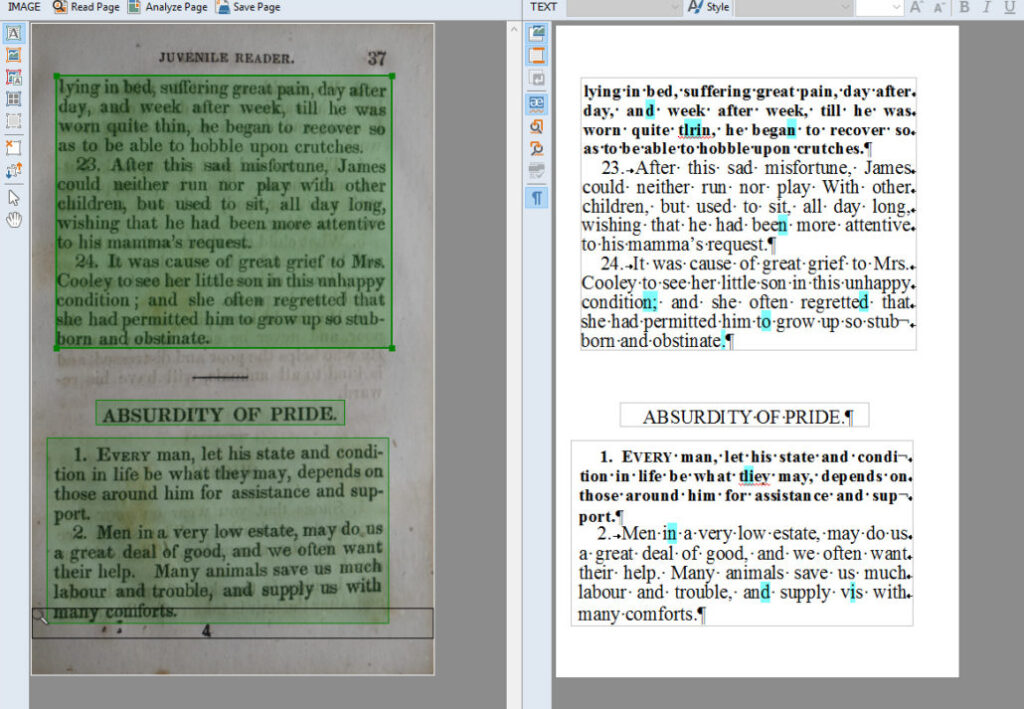
Optical Character Recognition (OCR) is a transformative technology that converts documents such as scanned papers, PDFs, or images into editable and searchable ...
6 min read
OCR
Document Processing
+5
Scene Text Recognition (STR) uses AI and deep learning to detect and interpret text in natural scenes, enabling smart automation in domains like vehicles, AR, and smart cities.
Scene Text Recognition (STR) is a branch of OCR focusing on identifying text in natural images. It uses AI for applications like autonomous vehicles and AR. Recent advancements involve vision-language networks and deep learning models to enhance accuracy.
Scene Text Recognition (STR) is a specialized branch of Optical Character Recognition (OCR) that focuses on identifying and interpreting text within images captured in natural scenes. Unlike traditional OCR, which deals with printed or handwritten text in controlled environments like scanned documents, STR operates in dynamic and often unpredictable settings. These include outdoor scenes with varying lighting, diverse text orientations, and cluttered backgrounds. The goal of STR is to accurately detect and convert textual information in these images into machine-readable formats.
Advancements in STR:
Recent research has introduced the concept of image as a language, employing balanced, unified, and synchronized vision-language reasoning networks. These advancements aim to mitigate the heavy reliance on a single modality by balancing visual features and language modeling. The introduction of models like BUSNet has enhanced the performance of STR through iterative reasoning, where vision-language predictions are used as new language inputs, achieving state-of-the-art results on benchmark datasets.
STR is a critical component of computer vision, leveraging artificial intelligence (AI) and machine learning to enhance its capabilities. Its relevance spans several industries and applications, such as autonomous vehicles, augmented reality, and automated document processing. The ability to accurately recognize text in natural environments is crucial for developing intelligent systems that can interpret and interact with the world in a human-like manner.
Technological Impact:
STR plays a pivotal role in various applications by providing near real-time text recognition capabilities. It is essential for tasks such as video caption text recognition, signboard detection from vehicle-mounted cameras, and vehicle number plate recognition. The challenges of recognizing irregular text due to variability in curvature, orientation, and distortion are being addressed through sophisticated deep-learning architectures and fine-grained annotations.
Scene Text Detection
Scene Text Recognition
Orchestration
Recent Developments:
The integration of vision-language reasoning networks and sophisticated decoding capacities are at the forefront of STR advancements, allowing for enhanced interaction between visual and textual data representations.
Industry Integration:
STR is increasingly used in smart city infrastructure, enabling automated text reading from public information displays and signage, which aids in urban monitoring and management.
Optimization Efforts:
Despite the challenges, optimization tools are being developed to reduce latency and improve performance, making STR a viable solution in time-sensitive applications.
In summary, Scene Text Recognition is an evolving field within AI and computer vision, supported by advancements in deep learning and model optimization techniques. It plays a pivotal role in developing intelligent systems capable of interacting with complex, text-rich environments, driving innovation across various sectors. The continuous development of vision-language reasoning networks and improved inference efficiencies promise a future where STR is seamlessly integrated into everyday technology applications.
Scene Text Recognition (STR) has become an increasingly significant area of research due to the rich semantic information that texts in scenes can provide. Various methodologies and techniques have been proposed to enhance the accuracy and efficiency of STR systems.
Notable Research Efforts:
A pooling based scene text proposal technique for scene text reading in the wild by Dinh NguyenVan et al. (2018):
This paper introduces a novel technique inspired by the pooling layer in deep neural networks, designed to accurately identify texts in scenes. The method involves a score function exploiting the histogram of oriented gradients to rank text proposals. The researchers developed an end-to-end system that integrates this technique, effectively handling multi-orientation and multi-language texts. The system demonstrates competitive performance in scene text spotting and reading.
Read the full paper here.
ESIR: End-to-end Scene Text Recognition via Iterative Image Rectification by Fangneng Zhan and Shijian Lu (2019):
This research addresses the challenge of recognizing texts with arbitrary variations such as perspective distortion and text line curvature. The ESIR system iteratively rectifies these distortions using a novel line-fitting transformation to improve recognition accuracy. The iterative rectification pipeline developed is robust and requires only scene text images and word-level annotations, achieving superior performance on various datasets.
Read the full paper here.
Advances of Scene Text Datasets by Masakazu Iwamura (2018):
This paper provides an overview of publicly available datasets for scene text detection and recognition, serving as a valuable resource for researchers in the field.
Read the full paper here.
Scene Text Recognition (STR) is an AI-driven technology that detects and interprets text within natural scene images, as opposed to traditional OCR, which works on printed or handwritten text in controlled environments.
Unlike traditional OCR that works with scanned documents, STR operates in dynamic environments with varying lighting, orientations, and backgrounds, using advanced deep learning models to recognize text in real-world images.
STR is used in autonomous vehicles for reading road signs, in augmented reality for overlaying information, in smart city infrastructure, retail analytics, document digitization, and assistive technologies for the visually impaired.
STR employs deep learning architectures like CNNs and Transformers, vision-language reasoning networks, and model optimization tools such as ONNX Runtime and NVIDIA Triton Inference Server.
Key challenges include handling irregular text (varied fonts, sizes, orientations), cluttered backgrounds, and the need for real-time inference. Advances in attention mechanisms and model optimization are addressing these issues.
Discover how Scene Text Recognition and other AI tools can automate and enhance your business processes. Book a demo or try FlowHunt today.
Optical Character Recognition (OCR) is a transformative technology that converts documents such as scanned papers, PDFs, or images into editable and searchable ...
Discover how AI-powered OCR is transforming data extraction, automating document processing, and driving efficiency in industries like finance, healthcare, and ...
Text classification, also known as text categorization or text tagging, is a core NLP task that assigns predefined categories to text documents. It organizes an...

