AllenNLP
AllenNLP is a robust open-source library for NLP research, built on PyTorch by AI2. It offers modular, extensible tools, pre-trained models, and easy integratio...
4 min read
NLP
Open Source
+6
spaCy is a fast, efficient NLP library in Python, ideal for production with features like tokenization, POS tagging, and entity recognition.
spaCy is a robust open-source library tailored for advanced Natural Language Processing (NLP) in Python. Released in 2015 by Matthew Honnibal and Ines Montani, it is maintained by Explosion AI. spaCy is celebrated for its efficiency, user-friendliness, and comprehensive NLP support, making it a preferred choice for production over research-oriented libraries like NLTK. Implemented in Python and Cython, it ensures rapid and effective text processing.
spaCy emerged as a powerful alternative to other NLP libraries by focusing on industrial-strength speed and accuracy. While NLTK offers a flexible algorithmic approach suitable for research and education, spaCy is designed for quick deployment in production environments with pre-trained models for seamless integration. spaCy provides a user-friendly API, ideal for handling large datasets efficiently, making it suitable for commercial applications. Comparisons with other libraries, such as Spark NLP and Stanford CoreNLP, often highlight spaCy’s speed and ease of use, positioning it as an optimal choice for developers needing robust, production-ready solutions.
Tokenization
Segments text into words, punctuation marks, etc., while maintaining the original text structure—crucial for NLP tasks.
Part-of-Speech Tagging
Assigns word types to tokens like nouns and verbs, offering insights into the grammatical structure of the text.
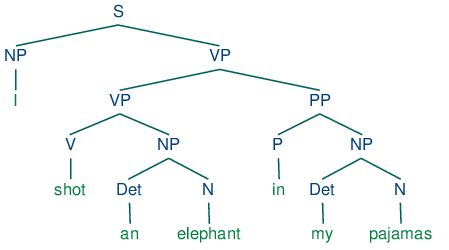
Dependency Parsing
Analyzes sentence structure to establish relationships between words, identifying syntactic functions such as subject or object.
Named Entity Recognition (NER)
Identifies and categorizes named entities in text, such as people, organizations, and locations, essential for information extraction.
Text Classification
Categorizes documents or parts of documents, aiding in information organization and retrieval.
Similarity
Measures similarity between words, sentences, or documents using word vectors.
Rule-based Matching
Finds token sequences based on their texts and linguistic annotations, akin to regular expressions.
Multi-task Learning with Transformers
Integrates transformer-based models like BERT, enhancing accuracy and performance in NLP tasks.
Visualization Tools
Includes displaCy, a tool for visualizing syntax and named entities, improving NLP analysis interpretability.
Customizable Pipelines
Allows users to customize NLP workflows by adding or modifying components in the processing pipeline.
spaCy is invaluable in data science for text preprocessing, feature extraction, and model training. Its integration with frameworks like TensorFlow and PyTorch is crucial for developing and deploying NLP models. For instance, spaCy can preprocess text data by tokenizing, normalizing, and extracting features like named entities, which can then be used for sentiment analysis or text classification.
spaCy’s natural language understanding capabilities make it ideal for developing chatbots and AI assistants. It handles tasks like intent recognition and entity extraction, essential for building conversational AI systems. For example, a chatbot using spaCy can understand user queries by identifying intents and extracting relevant entities, enabling it to generate appropriate responses.
Widely used for extracting structured information from unstructured text, spaCy can categorize entities, relationships, and events. This is useful in applications like document analysis and knowledge extraction. In legal document analysis, for instance, spaCy can extract key information such as parties involved and legal terms, automating document review and enhancing workflow efficiency.
spaCy’s comprehensive NLP capabilities make it a valuable tool for research and academic purposes. Researchers can explore linguistic patterns, analyze text corpora, and develop domain-specific NLP models. For example, spaCy can be used in a linguistic study to identify patterns in language use across different contexts.
Named Entity Recognition
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for ent in doc.ents:
print(ent.text, ent.label_)
# Output: Apple ORG, U.K. GPE, $1 billion MONEY
Dependency Parsing
for token in doc:
print(token.text, token.dep_, token.head.text)
# Output: Apple nsubj looking, is aux looking, looking ROOT looking, ...
Text Classification
spaCy can be extended with custom text classification models to categorize text based on predefined labels.
spaCy provides robust tools for packaging and deploying NLP models, ensuring production-readiness and easy integration into existing systems. This includes support for model versioning, dependency management, and workflow automation.
SpaCy is a widely used open-source library in Python for advanced Natural Language Processing (NLP). It is tailored for production use and supports various NLP tasks such as tokenization, part-of-speech tagging, and named entity recognition. Recent research papers highlight its applications, improvements, and comparisons with other NLP tools, enhancing our understanding of its capabilities and deployments.
| Title | Authors | Published | Summary | Link |
|---|---|---|---|---|
| Multi hash embeddings in spaCy | Lester James Miranda, Ákos Kádár, Adriane Boyd, Sofie Van Landeghem, Anders Søgaard, Matthew Honnibal | 2022-12-19 | Discusses the implementation of multi hash embeddings in spaCy to reduce memory footprint for word embeddings. Evaluates this approach on NER datasets, confirming design choices and revealing unexpected findings. | Read more |
| Resume Evaluation through Latent Dirichlet Allocation and Natural Language Processing for Effective Candidate Selection | Vidhita Jagwani, Smit Meghani, Krishna Pai, Sudhir Dhage | 2023-07-28 | Introduces a method for resume evaluation using LDA and spaCy’s entity detection, achieving 82% accuracy and detailing spaCy’s NER performance. | Read more |
| LatinCy: Synthetic Trained Pipelines for Latin NLP | Patrick J. Burns | 2023-05-07 | Presents LatinCy, SpaCy-compatible NLP pipelines for Latin, demonstrating high accuracy in POS tagging and lemmatization, showcasing spaCy’s adaptability. | Read more |
| Launching into clinical space with medspaCy: a new clinical text processing toolkit in Python | Hannah Eyre, Alec B Chapman, et al. | 2021-06-14 | Introduces medspaCy, a clinical text processing toolkit built on spaCy, integrating rule-based and ML approaches for clinical NLP. | Read more |
spaCy is an open-source Python library for advanced Natural Language Processing (NLP), designed for speed, efficiency, and production use. It supports tasks such as tokenization, part-of-speech tagging, dependency parsing, and named entity recognition.
spaCy is optimized for production environments with pre-trained models and a fast, user-friendly API, making it ideal for handling large datasets and commercial use. NLTK, on the other hand, is more research-oriented and offers flexible algorithmic approaches suitable for education and experimentation.
Key features include tokenization, POS tagging, dependency parsing, named entity recognition, text classification, similarity measurement, rule-based matching, transformer integration, visualization tools, and customizable NLP pipelines.
spaCy is widely used in data science for text preprocessing and feature extraction, in building chatbots and AI assistants, for information extraction from documents, and in academic research for analyzing linguistic patterns.
Yes, spaCy can be integrated with frameworks like TensorFlow and PyTorch, allowing seamless development and deployment of advanced NLP models.
Yes, spaCy's flexible API and extensibility allow it to be adapted for specialized domains, such as clinical text processing (e.g., medspaCy) and legal document analysis.
Discover how spaCy can power your NLP projects, from chatbots to information extraction and research applications.
AllenNLP is a robust open-source library for NLP research, built on PyTorch by AI2. It offers modular, extensible tools, pre-trained models, and easy integratio...
Natural Language Toolkit (NLTK) is a comprehensive suite of Python libraries and programs for symbolic and statistical natural language processing (NLP). Widely...
Gensim is a popular open-source Python library for natural language processing (NLP), specializing in unsupervised topic modeling, document indexing, and simila...